Common Core: High School - Statistics and Probability : Interpreting Categorical & Quantitative Data
Study concepts, example questions & explanations for Common Core: High School - Statistics and Probability


All Common Core: High School - Statistics and Probability Resources
Example Questions
Example Question #61 : Interpreting Categorical & Quantitative Data
A student scores a on the Scholastic Assessment Test (SAT). A college admissions committee does not know how the exam is scored; however, they do know the scores of the exam form a normal distribution pattern. They also know the mean score and standard deviation of the population of students that took the test.


Using this information, determine whether or not the student scored well on the SAT.
The student scored very well: above two standard deviations of the mean.
The student scored poorly: below a single standard deviation of the mean.
The student scored well: above a single standard deviation of the mean.
The student scored very poorly: below two standard deviations of the mean.
The student's score was average: similar to the mean.
The student scored poorly: below a single standard deviation of the mean.
In order to solve this problem, let's consider probabilities and the normal—bell curve—distribution. Given that all events are equally likely, probability is calculated using the following formula:

When probabilities of a given population are calculated for particular events, they can be graphed in a frequency chart or histogram. If they form a standard distribution, then the graph will form to the following shape:

This shape is known as a bell curve. In this curve, the mean is known as the arithmetic average and is represented as the peak. The mean alters the position of the graph. If the mean increases or decreases, then the graph shifts to the right or to the left respectively. The mean is denoted as follows:

On the other hand, the standard deviation is a calculation that indicates the average amount that each value deviates from the mean. When the standard deviation is changed then the shape of the graph is altered. When the standard deviation is decreased, the graph is taller and thinner. Likewise, when the standard deviation is increased, the graph becomes shorter and wider. It is important to note that 99.7 percent of all the values in a normal population exist between three standard deviations above and below the mean. It is denoted using the following annotation:

Now that we have discussed the components of the bell curve, let's consider the scenario presented in the question.
We know that the distribution of test scores follows a normal curve. We also know the following values:

We should first plot the data on a graph that follows the shape of a bell shaped curve with three standard deviations.

We know that the student had the following score:

Let's calculate one standard deviation below the mean.

The student scored poorly: below a single standard deviation of the mean. Notice that at this point on the graph, the tail of the curve is closer to the horizontal or x-axis. This means that fewer students scored this low on the exam. In other words, the student performed poorly.
Example Question #62 : Interpreting Categorical & Quantitative Data
A student scores a on the Scholastic Assessment Test (SAT). A college admissions committee does not know how the exam is scored; however, they do know the scores of the exam form a normal distribution pattern. They also know the mean score and standard deviation of the population of students that took the test.


Using this information, determine whether or not the student scored well on the SAT.
The student's score was average: similar to the mean.
The student scored well: above a single standard deviation of the mean.
The student scored very poorly: below two standard deviations of the mean.
The student scored very well: above two standard deviations of the mean.
The student scored poorly: below a single standard deviation of the mean.
The student scored very poorly: below two standard deviations of the mean.
In order to solve this problem, let's consider probabilities and the normal—bell curve—distribution. Given that all events are equally likely, probability is calculated using the following formula:
When probabilities of a given population are calculated for particular events, they can be graphed in a frequency chart or histogram. If they form a standard distribution, then the graph will form to the following shape:
This shape is known as a bell curve. In this curve, the mean is known as the arithmetic average and is represented as the peak. The mean alters the position of the graph. If the mean increases or decreases, then the graph shifts to the right or to the left respectively. The mean is denoted as follows:
On the other hand, the standard deviation is a calculation that indicates the average amount that each value deviates from the mean. When the standard deviation is changed then the shape of the graph is altered. When the standard deviation is decreased, the graph is taller and thinner. Likewise, when the standard deviation is increased, the graph becomes shorter and wider. It is important to note that 99.7 percent of all the values in a normal population exist between three standard deviations above and below the mean. It is denoted using the following annotation:
Now that we have discussed the components of the bell curve, let's consider the scenario presented in the question.
We know that the distribution of test scores follows a normal curve. We also know the following values:
We should first plot the data on a graph that follows the shape of a bell shaped curve with three standard deviations.
We know that the student had the following score:

Let's calculate two standard deviations below the mean.
=495-(2 \times 116)= 263")
The student scored very poorly: below two standard deviations from the mean. Notice that at this point on the graph, the tail of the curve is closer to the horizontal or x-axis. This means that fewer students scored this low on the exam. In other words, the student performed very poorly.
Example Question #61 : High School: Statistics & Probability
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:
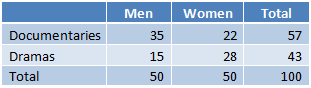
What is the relative probability of men who prefer dramas?




This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:
Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:

In this table we can see that the relative probability of men who like dramas is:



This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:

Example Question #62 : High School: Statistics & Probability
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:
What is the conditional probability of men who like documentaries?




This question requires us to calculate a conditional probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:
Conditional probabilities are calculated by dividing a joint frequency by a marginal frequency. In this case we need to divide the number of men who like documentaries by the total number of men in the study (i.e. the two conditions we know).



Example Question #63 : High School: Statistics & Probability
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:
What is the relative probability of men who prefer dramas?





This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:
Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:
In this table, we can see that the relative probability of men who like dramas is:
This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:
Example Question #64 : High School: Statistics & Probability
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:
What is the conditional probability of men who like documentaries?

This question requires us to calculate a conditional probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:
Conditional probabilities are calculated by dividing a joint frequency by a marginal frequency. In this case we need to divide the number of men who like documentaries by the total number of men in the study (i.e. the two conditions we know).
Example Question #5 : Summarize Interpret Categorical Data In Two Way Frequency Tables: Ccss.Math.Content.Hss Id.B.5
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:
What is the relative probability of men who prefer dramas?
This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:
Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:
In this table we can see that the relative probability of men who like dramas is:
This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:
Example Question #6 : Summarize Interpret Categorical Data In Two Way Frequency Tables: Ccss.Math.Content.Hss Id.B.5
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:

What is the relative probability of men who prefer dramas?





This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:

Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:

In this table, we can see that the relative probability of men who like dramas is:

This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:

Example Question #7 : Summarize Interpret Categorical Data In Two Way Frequency Tables: Ccss.Math.Content.Hss Id.B.5
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:

What is the relative probability of men who prefer dramas?





This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:

Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:

In this table, we can see that the relative probability of men who like dramas is:

This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:

Example Question #8 : Summarize Interpret Categorical Data In Two Way Frequency Tables: Ccss.Math.Content.Hss Id.B.5
Suppose a social scientist wants to know the effects of gender upon film preferences. She samples fifty men and women and asks them to mark their preference between to genres: documentaries and dramas. She then constructs a two-way frequency table as shown:

What is the relative probability of men who prefer dramas?





This question requires us to calculate a relative probability from a two-way frequency chart. Before we can calculate this probability, we need to consider the composition of these tables. The numbers located within the table are not quantitative (i.e. they simply represent the number of times a particular phenomenon occurs). These tables are made up of marginal and joint frequencies. Marginal frequencies occur in the columns and rows labeled as “titles,’” while the joint frequencies are embedded in the table. Let’s observe the frequency table given in the question:

Relative probabilities are calculated by dividing the marginal and joint frequencies by the total in the table. If we divide each frequency by the total frequency, then we can create the following table:

In this table, we can see that the relative probability of men who like dramas is:

This can also be solved by graphing the relative probabilities on a stacked bar chart such as the one shown below:


Certified Tutor

Certified Tutor

All Common Core: High School - Statistics and Probability Resources

